For as long as I can remember, the standard approach to web development has been a monolithic one. A database at the bottom, some business logic in the middle and maybe an API interface for communicating against a SPA client.
For most applications these object oriented CRUD solutions work just fine. However there are a couple of shortcomings in this traditional architecture, which I hope to shine some light upon with this post.
For a couple a years ago I was introduced to the fairly old concept of CQRS (Command and Query Responsibility Segregation) and Event Sourcing. And ever since learning about this fundamentally different way of developing applications, I knew that i was bound to someday (when I had the time) to try this out first hand. Apparently this day has now arrived.
I’m not going to go into great detail on these subjects, instead i’m going to show a simple Todo application I have written using a simplified version of the the principles in CQRS and EventSourcing.
However, the short version is that CQRS is basically a form of separation of concerns, where you deliberately split your application into one part that handles all the writing and one that handles all the reading. This is usually done through Command and Query messages/objects.
EventSourcing on the other hand is a way of persisting state, however instead of just persisting the latest state (like you would in a traditional relational database) you instead store all state changes that has happened over time.
Now let’s imagine for a moment that you and me, the reader and author are both developers, and we have both been tasked with creating a simple Todo application with the following requirements:
- A user should be able to create/edit and remove a Todo
- A Todo has a small text and is either completed or not.
- A user should be able to view a list of all Todo’s in the system
You decide upon a simple CRUD application that would look something like the following.
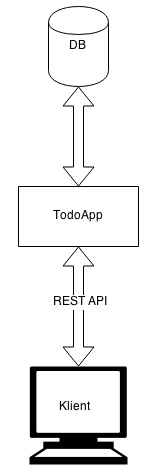
In addition you create a list of the process flow.
Create
- Client issues a POST call to “/todo”
- API interface receives the request and converts the payload to the local Todo data model and passes it on to the DAO
- The DAO issues the necessary DB queries which stores the entity in the database.
- The API interface converts the Todo object into json and transmits it to the client.
- Client does any necessary view processing.
Update
- Client issues a PUT call to “/todo/{id}”
- API interface receives the request and converts the payload to the local Todo data model and passes it on to the DAO
- The DAO issues the necessary DB queries which replaces the entity in the database.
- The API interface converts the Todo object into json and transmits it to the client.
- Client does any necessary view processing.
Remove
- Client issues a DELETE call to “/todo/{id}”
- API interface receives the request and executes a remove instruction on the DAO based upon the id parameter.
- The DAO issues a DB delete query which removes the todo data.
- The API interface then returns with success to the client.
- Client does any necessary view processing.
Retrieve a Todo
- Client issues a GET call to “/todo/{id}”
- API interface receives the request and calls the DAO to fetch a Todo by id
- The DAO issues a DB query and converts the result into the local Todo data model.
- The API interface then converts this Todo entity into a json object and puts it on the network connection to the client.
- Client does any necessary view processing.
Retrieve all Todo’s
- Client issues a GET call to “/todo/all”
- API interface receives the request and calls the DAO to fetch all Todo’s
- The DAO issues a DB query and converts the result into a list of the local Todo data model.
- The API interface then converts this list of Todo entities into a list of json objects and puts it on the network connection to the client.
- Client does any necessary view processing.
Meanwhile I decided on another approach (you guessed it!) with CQRS and Event Sourcing. The basic structure would look something like the following:
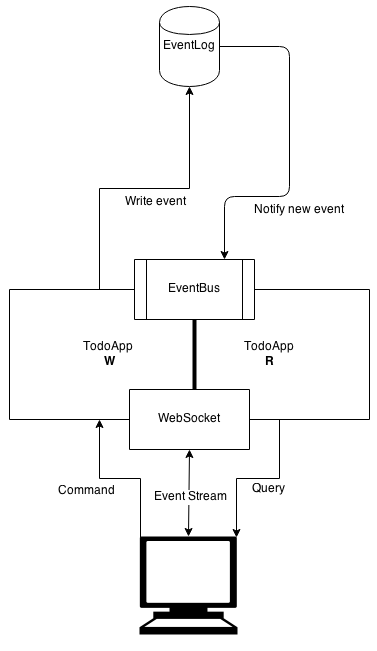
As you can see the structure is quite different from the simple CRUD application, but as are the processes of the application. As an extra but not required feature for this application I added websockets functionality which basically lets clients subscribe to events so that it’s possible to have realtime data updates in client views.
Create/Update/Remove
On the write side.
- Client issues a POST call to “/cmd”
- API interface receives the request and converts the payload to a CommandMessage and passes it on to the responsible command handler
- The handler creates one of the following events, based upon the command type and then persists it to the eventlog
- TodoItemCreatedEvent
- TodoItemRemovedEvent
- TodoItemUpdatedEvent
- The eventbus is then notified of the event and publishes it to all listeners of that type of event
Meanwhile on the read side.
- The TodoProjection is notified of the event and processes it accordingly
- TodoItemCreatedEvent – Creates a new json formatted file which the todo is represented in (i.e dacbe19c-237c-4672-a8e0-319eff1dbc25.json) and also adds the json to a collection of all todos in the file all.json.
- TodoItemRemovedEvent – Removes static file (i.e dacbe19c-237c-4672-a8e0-319eff1dbc25.json) and removes todo from all.json
- TodoItemUpdatedEvent – Replaces the contents the todo’s json file and its occurence in all.json
- In parallel the websocket is also notified of the event and publishes this to all the clients connected to the application
- Client does any necessary view processing.
Retrieve a Todo
- Client issues a GET call to “/todo/dacbe19c-237c-4672-a8e0-319eff1dbc25.json”
- The server transfers the static file dacbe19c-237c-4672-a8e0-319eff1dbc25.json
- Client does any necessary view processing.
Retrieve all Todo’s
- Client issues a GET call to “/todo/all.json”
- The server serves the static file all.json
- Client does any necessary view processing.
Comparison
The biggest difference between the two solutions is that in the ES application the main source of data is the event-log, the event-log is a recording of all events ever created in the system which has total ordering and should never be modified, only appended to. This makes this application an event-driven system, where reads and writes are asynchronous/non-blocking. However in the CRUD application you have a database as its fundamental piece, where only the latest data is stored.
Every time you start the ES application it will read the event-log from start to end and pass the events to all listeners through the event-bus. In my application I store each event on a new line in a single file formatted as JSON. When the application starts, it reads the file, line by line (one event at a time) and converts it from JSON to my event model and passes it on the the event-bus which includes notifying TodoProjection. The TodoProjection listener creates the views (JSON files) for the client SPA.
You may think that the event-log will get extremely huge and that processing it is a very time consuming operation, but actually it isn’t a problem at all. The events recorded in the event-log is usually quite small, and especially if you use a binary log, in addition in EventSourcing there is a concept of snapshots. If your event log where to grow to a size where it would take too long to process for each time you would restart the application. Then we could simply create a snapshot and tell the application to only read events from a given point in time.
The fact that all state has been stored over time in the event log gives us the ability to see how the application looked like a month ago. We would also be able to see things like “how many Todo’s have been deleted in the system”. If you were to do this type of thing in a relational database, you would usually create some sort of auditing table which stores state changes. However this introduces business logic/code that needs to be maintained across the entire application.
Now if we compare the two solutions in terms of the applications operations, we see that the CRUD application does quite a lot of work and data transformation regardless if it’s a write or read operation (create a Todo vs. read a Todo), while the ES application has a lightning fast read operation and a somewhat slower write operation. However I would still argue that the write operation is faster than CRUD’s solution, as it has this split architecture of non-blocking read and write and reads & write could be run in parallel.
In the CRUD application there is no process that acts like a TodoProjection that generates the client views like there is in the ES application. Here instead we need to transform the data from the DB to the data model, and then into the representation the client requires. This is a lot of data transformation for each time a client queries some resource through the API. However it is also very convenient for development as all data that is stored in the DB is ready to be sorted, indexed and even searched upon, but it comes at the cost of performance.
In my application I could have opted for storing views in a traditional database giving me more dynamic features like sorting and indexing, another approach would be to create new business logic that generate JSON files with the required views you need, or you could even index and sort the dataset in the client SPA, however for very large datasets we are probably better off using some sort of database and/or search engine in order to store our views.The interesting thing about striving for representing data in the format the client requires them is that the generated views and cached views are identical, effectively making any caching solution obsolete!
Another great feature of ES is in it’s flexibility, in a ES application you can more easily split off the application into parts of separate concerns. For example, one part of the system which doesn’t have complex view requirements like sorting, filtering and indexing, could store its data as json files, while another part with say large datasets might be better off using a search engine or a database of some kind as its main view storage. In addition as a ES application can be split up, so can scaling. Instead of having to scale the entire application you can scale the parts that has the largest amount of traffic.
Scaling
So let’s imagine for a second that our Todo application is a roaring success, with increased traffic we now require more optimizations, caching and scaling. So let’s look a bit into how scaling these two applications would look like.
In the CRUD application we would typically see a structure like this:
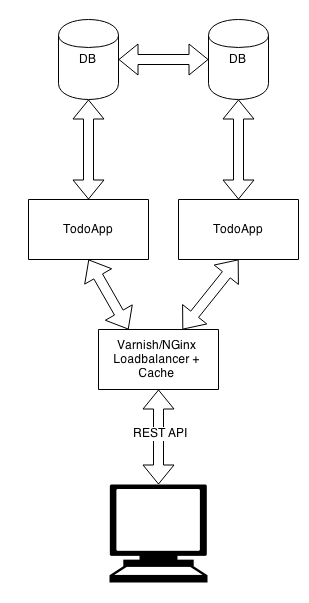
A replicated database with a master and slave instance, then two instances of the application and at the DMZ we have a loadbalancer with some kind of caching solution. As a side note, it’s also a good idea to have 2nd level caching between the database and the application, however I haven’t included this in the drawing.
With a architecture like this we would have the flexibility to scale on the number of database instances and application instances, but that is really where it ends.
In addition we have a problem with utilizing caching, the problem being that we need to add caching rules to the application. For instance, if a single Todo resource were cached, then we need to refresh that cache whenever a update is done on that Todo. In a worst case scenario this means that the application would have to add code that manages cache in it’s business logic, which pollutes your code with complexity and ad decreases readability, it also makes it harder to test the code as it now depends on a third party presence.
For the ES application a architecture like the following would probably suffice:
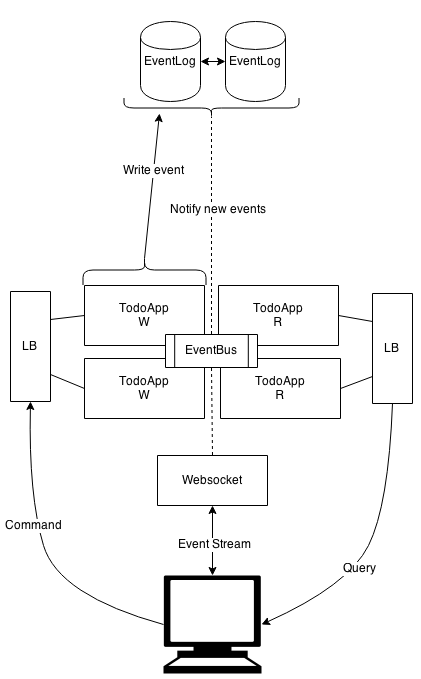
Here we can see we have a replicated event-log as our main storage, we have some way of communication between the application and websocket server through the event bus and we have two instances of the write side of the application and two instances of the read side of the application, both with their own loadbalancer as entry, although strictly speaking we could probably suffice with only one loadbalancer.
In terms of scaling we have a lot of flexibility here, if we have a very read intensive application, we would only need to scale the read side of the application and vice versa if we have high traffic on the write side. In addition if we split up the application into even smaller bits, one could imagine it possible to scale those tiny parts of the system individually.
Summary
So what is the benefits of using a CQRS+ES architecture?
- You get auditing for free.
- Data are now streams of events, which enables the two outer points of the application (backend and client) to be in sync.
- Highy performant and scales better/smarter.
- No need for caching solutions, atleast not in my example (application requirements may vary).
Now that being said, you can get almost all of this with a standard CRUD application as well.
- Auditing in CRUD? Yes it’s possible, but it requires you to code for it, maintain and test it.
- Realtime events with clients? Yes also possible, but comes at a cost for coding/testing.
- Highly performant and scalable? Not to even close to the same degree a CQRS+ES application. However, you only need to scale it to the traffic you are expecting.
- Caching solution required? Not necessarily, you could probably skip the database all together, or even have two data models, one in the database and one in JSON. However this could get messy, and besides the overall trend is to only have data in the database with this traditional architecture.
The best part however (in my opinion) with a CQRS+ES application is that projections can format the data to the same format expected by the end clients, and by doing so we don’t have to rely on any caching solution as we normally would. This means that every read operation simply transfers the preformatted data straight to the client.
I also like the fact that our main data is in the form of events, enabling realtime data through a websockets connection to the client. So for all state changes we simply push that state to every client listening, which makes this application highly reactive!
The following is a video is a demonstration of my Todo application written in Go and AngularJS, which shows the realtime aspect of the application when several clients are connected.
My next adventure
This is as far as I go with this blog post for now. Next up is to check out how a ES application would look like in an multi context environment with for instance user authentication and filtering of content/events based on user privileges.
How would developing an application using CQRS and ES compare in development speed compared to CRUD applications which has hundreds of rapid web development frameworks to choose from?
Would it be possible to create a mini web framework/scaffolding which creates a simple CQRS+ES application with websockets for realtime connectivity as well as the parts needed in a SPA application?
Final thoughts
If you are interested in the code, feel free to look it up at my github project page. I must warn you however, the application is just a simple test application, it’s loaded with race conditions. So do not try to put it under any load test and expect it to work.
If you wish to learn more about CQRS/ES and the Event Driven architecture I would recommend the following:
And as a parting gift, here’s a fun fact for you. Did you know that almost all transactional RDBMS systems use a transaction log for storing all changes applied to the database? This basically means that the database could be reconstructed with this log. You are in a sense already doing EventSourcing if you are using a RBDMS, you just can’t access the the events in a simple way.